What an AI engineer actually does in a chat window
I gave Claude one prompt this morning:
“Investigate this tenant. It has to be migrated to NSX-T this weekend, but it has IPv6. We need a plan. Investigate first if the tenant is actually using IPv6 and for what purpose.”
Two and a half hours later: a Confluence assessment page, a Jira ticket with full scope, deployed config on two Juniper MX204s and an NSX-T Tier-0 (six BGP sessions brought up), and a worklog entry summarising the whole thing. End-to-end. In a single chat window.
I want to talk less about what the change was (a fairly normal IPv6 BGP enablement between NSX-T and an upstream Juniper) and more about how Claude actually got the work done. Because the workflow it ran is genuinely the thing.
The investigation
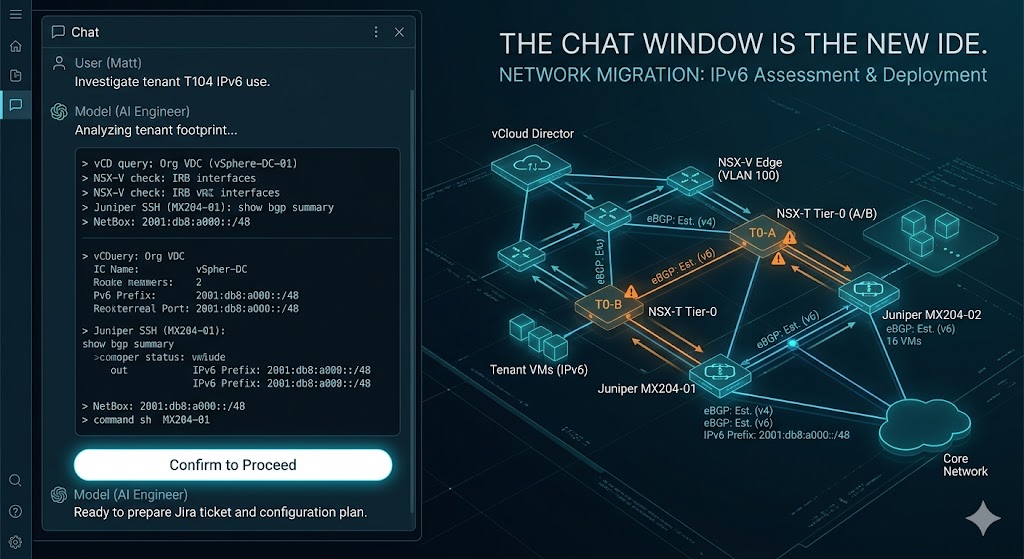
It started with a tenant ID. Claude pulled the tenant footprint from vCloud Director — org, vDC, edge gateway, networks, VMs. Found one internal LAN, nine running VMs, an NSX-V edge.
Then it followed the IPv6 trail without me having to tell it where to look:
- Inspected the NSX-V edge interface config to find IPv6 IRBs.
- Pulled the edge firewall rules — found exactly one rule referencing a single v6 destination.
- Did a
dig AAAAon the suspected hostname, got that exact address back. - Did a TLS handshake on the v4 NAT IP and parsed the certificate. Subject CN matched the AAAA record’s hostname.
End-to-end evidence chain: one VM, one TCP port, one public IPv6 address, statically configured inside the guest. That was the entire IPv6 footprint.
It then asked itself the next obvious question — who owns the IPv6 prefix this address comes from? — and delegated that lookup to a NetBox specialist subagent that ran in parallel while it kept investigating. Came back with: it’s a per-customer carve-out from our PA aggregate, and (incidentally) was never registered in NetBox. Logged that as a follow-up housekeeping item.
While that was running, Claude SSH’d into the upstream Juniper MX204s via PyEZ and traced the IPv6 next-hop. Found the static route currently carrying that prefix to the NSX-V edge: pref-5, sitting there for six weeks.
It also queried the NSX-T fabric to check whether the destination Tier-0 was IPv6-ready. It wasn’t — no IPv6 transit subnet, no IPv6 BGP family on either neighbor, no v6 addresses on any of six uplink interfaces.
That’s six different systems queried — vCloud, NSX-V, DNS, TLS, NetBox, NSX-T, plus two Junos devices via NETCONF — to produce a single coherent picture. Every datum verified against the live system, not from documentation.
The assessment
Claude wrote up a Confluence page summarising the investigation: tenant identity, workload inventory, the IPv6 footprint with full evidence chain, the prefix ownership picture from NetBox, the upstream MX routing, the Tier-0 readiness gap, and a recommended migration plan with three options ranked by risk. About 800 lines of structured HTML, posted to the right space, parented under the right folder.
I didn’t ask for the page. It produced the page because it understood the situation warranted documentation.
The ticket
Once we’d discussed the plan and I’d picked an approach, Claude wrote a Jira ticket. Not a thin “do the BGP” ticket — a full one:
- Summary, background, link to the investigation page.
- Current state for both NSX-T and the MX204s, captured live.
- Step-by-step scope across NetBox prefix allocation, MX204 IRB v6 addressing, new BGP groups + policies, T0 v6 uplinks/transit/BGP, and a legacy static removal step.
- Four design-review questions explicitly called out as needing resolution before commit.
- A test plan.
- A rollback plan.
- An out-of-scope section so reviewers wouldn’t have to guess.
Posted via the Jira REST API with proper Atlassian Document Format formatting. Started in Backlog (per the team’s workflow). I moved it to In Progress after a quick read.
The deploy
This is where it gets interesting.
For the Junos side, Claude used the in-house Junos deployment skill. The skill is just a thin wrapper around NETCONF/PyEZ, but it does the right things: locks the candidate config, runs commit-check before commit, includes a commit comment that references the ticket, posts an audit comment back to Jira automatically, and writes a session log to disk. The skill also refuses to deploy unless the linked Jira ticket is in Ready for Team or In Progress — a hard guardrail enforced by the script, not by polite request.
Claude proposed the diff in chat first. I confirmed. It deployed to one router, verified, deployed to the second router, verified again. Committed.
Then it pivoted, mid-deploy, on a real surprise — the BGP groups it was about to “create” already existed, with a working session for an unrelated tenant inside them. The originally-approved diff would have replaced that tenant’s MD5 key and silently dropped their session.
Claude noticed during the dry-run, stopped, told me what it had found, proposed a smaller scope (additive-only, no group-level edits), and waited for me to re-confirm the new diff. That’s the bit that matters. The model didn’t push through. It surfaced the conflict, explained the implication, and asked.
The NSX-T side
For the NSX-T Tier-0 changes, Claude used a different skill — the NSX-T policy API skill. Different system, different idiom (REST + JSON instead of NETCONF + XML), different conventions. It planned the changes:
- Create a DISABLED-RA NDRA profile so adding v6 to the uplinks wouldn’t leak Router Advertisements at the upstream router.
- PATCH each of six T0 uplink interfaces to add the v6 subnet and attach the NDRA profile.
- Create two new BGP neighbors over IPv6 transport.
Then it hit a real bug. The first PATCH on an interface object accidentally cleared edge_path to null — NSX-T policy API “PATCH” turns out not to be strictly partial; fields you don’t include can be wiped. The IPv4 BGP from that edge stayed up because the dataplane hadn’t re-realized yet, but a follow-up GET caught it.
Claude restored the dropped field with another PATCH, verified the v4 BGP hadn’t flapped (flap_count: 0), then PATCHed the remaining five interfaces with edge_path explicitly included. Then created the two BGP neighbors.
I did not have to coach it through this. The model recognised the mistake, recovered, and continued. It also wrote up the recovery in the ticket comment — “first PATCH dropped edge_path, restored it before any BGP flap, lesson logged: always include identity-binding fields in T0-interface PATCH bodies.”
Verification
After everything was deployed, Claude verified across both systems:
- NSX-T policy API for BGP neighbor status (the NSX-T endpoint actually returned an internal server error, so it fell back to checking from the MX side — fine).
- PyEZ on both MX204s for
peer-stateon every BGP session: six new IPv6 sessions Established, six existing IPv4 sessions still Established withflap_count: 0, and the unrelated tenant’s IPv6 session still Established and unaffected. show route advertising-protocol bgp <peer> table internet.inet6.0to confirm the upstream was actually advertising the IPv6 default route to the new sessions.
Then it commented the post-deploy state on the Jira ticket, appended a worklog entry to the running monthly Confluence worklog page, and marked all the tracked tasks complete. End of run.
The patterns that make it work
A few things stand out about how this actually came together.
Skills as a tool layer. Claude doesn’t natively know about vCloud Director or NSX-T policy API or Junos NETCONF. It uses skills — small wrappers I’ve built over time, each scoped to one system. The Junos skill, for instance, doesn’t just run commands; it enforces ticket-approval before deploy, posts audit trails, and runs commit-check before commit. The skill is the contract — once it exists, Claude can use it correctly without rediscovering each system’s idioms in every conversation.
Memory. Claude knew which routers terminated which BGP sessions because the topology is in a memory file (a one-line summary of every datacenter router with its role, model, and naming pattern). It knew the management network credentials live in a Bitwarden vault accessible via a wrapper. It knew the worklog page IDs and the auto-append protocol. None of that had to be in the prompt — it was already in context from previous sessions. Two years of cumulative institutional context, without me retyping it.
Subagents for parallelism. When Claude needed a NetBox lookup, it spawned a NetBox-specialist subagent in parallel and kept investigating. When it wanted a sanity check on its plan before committing to a substantial change, it called an advisor subagent — a stronger model with the full conversation transcript — for a second opinion. That second opinion is what caught the “shared BGP groups, you’ll break another tenant” issue before any commit happened.
Human-in-the-loop on blast-radius. Claude is not trying to be autonomous on production network changes. Every time the proposed action had multi-tenant or cross-system consequences — deploying Junos config, modifying NSX-T BGP, creating a Jira ticket, even just changing the proposed scope — it stopped and asked. The chat window has a lot of “Confirm to proceed?” messages. That’s the model behaving correctly, not failing to act.
Audit trail back into the existing systems. Every change went into Jira (auto-comment from the deploy script + a more detailed manual comment), Confluence (assessment page + worklog entry), and the local audit log on disk (NETCONF session log). There’s no AI-only output. Everything Claude did is visible to the rest of the team in the systems they already use.
What’s actually new
I’ve been doing network engineering long enough to remember when “automation” meant Ansible playbooks that someone wrote, version-controlled, and ran by hand. Then it meant CI/CD pipelines that ran those playbooks on a trigger. Then it meant Terraform modules with proper state.
This is different. The investigation, the assessment doc, the ticket scope, the deploy, the recovery, the verification, the worklog entry — none of it was scripted ahead of time. There’s no playbook called migrate_v6_tenant.yml. The model figured out what to do based on the situation it found, used the skills available to it, asked for confirmation when the blast radius warranted it, and produced artefacts that fit the team’s existing change-management practice.
The skills layer matters enormously. Without it, you get a chatbot that can describe what should happen but can’t make it happen. With skills that wrap real APIs, enforce the right safety guardrails, and integrate with the team’s audit systems, you get something that can operate as a junior engineer who happens to know every system in the stack. With memory that persists across conversations, you get one who already knows your topology.
I’d estimate I spent maybe 30 minutes of focused attention on this entire change — mostly reading proposed diffs, choosing between design options, and confirming deploys. The other two hours of work happened in a chat window while I did other things.
It’s hard to overstate how different that feels from doing the same change by hand. And I’m not sure the people deciding what AI is “for” yet realise this is the shape of it. Not chatbots. Not code copilots. Engineers in a chat window who can read your stack, plan a change, and deploy it through the same systems you’d use yourself — with you in the loop on the consequential moments and out of it for the rest.
The takeaway, if there is one: stop thinking about AI as a thing that generates text. Start thinking about it as a thing that operates the systems you’ve already built, given the right interface and the right guardrails. The interface is the skill. The guardrail is the human still being asked before anything irreversible happens. Get those right and the rest is just iteration.